
Citing NDIF
If you use NNsight or NDIF resources in your research, please cite the following:
Citation
Jaden Fried Fiotto-Kaufman, Alexander Russell Loftus, Eric Todd, Jannik Brinkmann, Koyena Pal, Dmitrii Troitskii, Michael Ripa, Adam Belfki, Can Rager, Caden Juang, Aaron Mueller, Samuel Marks, Arnab Sen Sharma, Francesca Lucchetti, Nikhil Prakash, Carla E. Brodley, Arjun Guha, Jonathan Bell, Byron C Wallace, and David Bau. "NNsight and NDIF: Democratizing Access to Foundation Model Internals," ICLR 2025. Available at https://openreview.net/forum?id=MxbEiFRf39.
BibTex
@inproceedings{fiotto-kaufman2025nnsight,
title={{NNsight} and {NDIF}: Democratizing Access to Foundation Model Internals},
author={Jaden Fried Fiotto-Kaufman and Alexander Russell Loftus and Eric Todd and Jannik Brinkmann and Koyena Pal and Dmitrii Troitskii and Michael Ripa and Adam Belfki and Can Rager and Caden Juang and Aaron Mueller and Samuel Marks and Arnab Sen Sharma and Francesca Lucchetti and Nikhil Prakash and Carla E. Brodley and Arjun Guha and Jonathan Bell and Byron C Wallace and David Bau},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=MxbEiFRf39}
}
In addition, when you publish work using NNsight or NDIF resources, we'd love you to email us directly at info@ndif.us to tell us about your work. This helps us track our impact and supports our continued efforts to provide open-source resources for reproducible and transparent research on large-scale AI systems.
Research Using NDIF
![]() Julien Siems, Timur Carstensen, Arber Zela, Frank Hutter, Massimiliano Pontil, Riccardo Grazzi.
DeltaProduct: Improving State-Tracking in Linear RNNs via Householder Products.
Julien Siems, Timur Carstensen, Arber Zela, Frank Hutter, Massimiliano Pontil, Riccardo Grazzi.
DeltaProduct: Improving State-Tracking in Linear RNNs via Householder Products.
This paper presents DeltaProduct, a linear RNN that improves expressivity while maintaining efficiency by using a diagonal plus rank-nh transition matrix built from Householder transforms. It outperforms DeltaNet in state tracking, language modeling, and length extrapolation, and the authors also provides new theoretical insights, showing that DeltaNet can solve dihedral group word problems in just two layers.
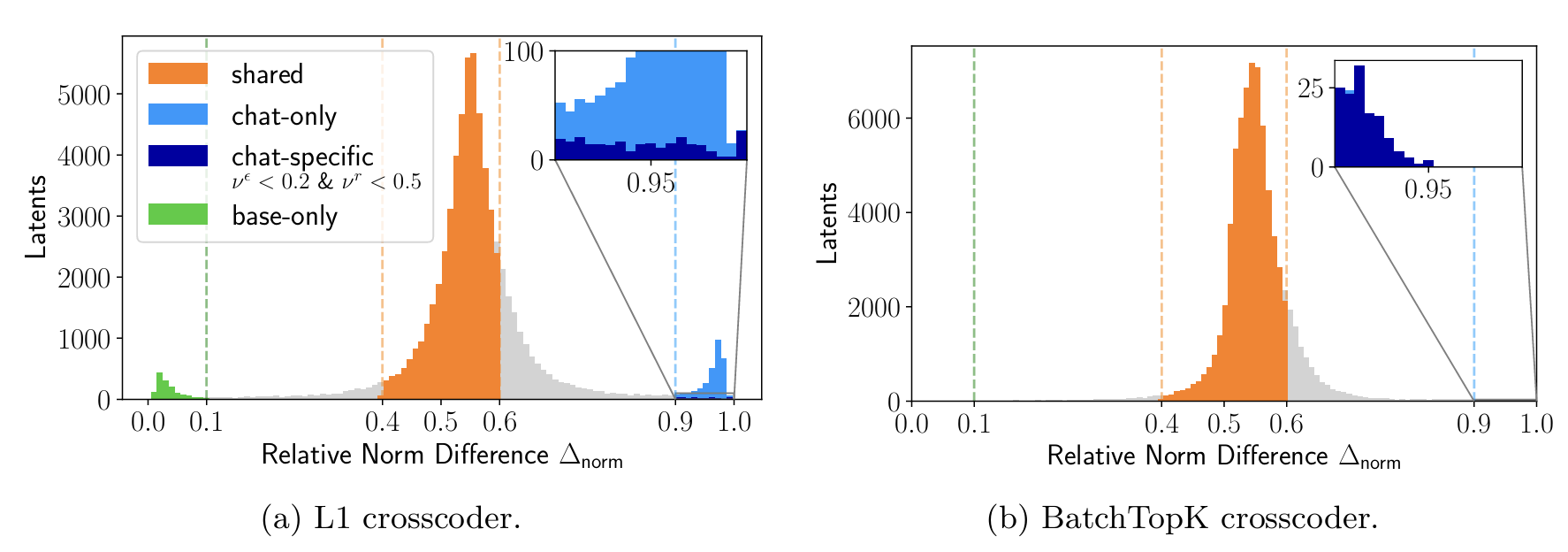 Julian Minder, Clement Dumas, Caden Juang, Bilal Chugtai, Neel Nanda.
Robustly identifying concepts introduced during chat fine-tuning using crosscoders.
Julian Minder, Clement Dumas, Caden Juang, Bilal Chugtai, Neel Nanda.
Robustly identifying concepts introduced during chat fine-tuning using crosscoders.
Improves model diffing techniques for understanding how fine-tuning alters language model behavior. The authors identify flaws in the standard crosscoder method that lead to misattributing shared concepts as fine-tuning-specific. They introduce Latent Scaling to better measure concept presence across models and propose a new BatchTopK loss that avoids these issues. Their method uncovers chat-specific, interpretable latents (e.g., latents tied to refusals or misinformation) offering clearer insights into the effects of chat tuning.
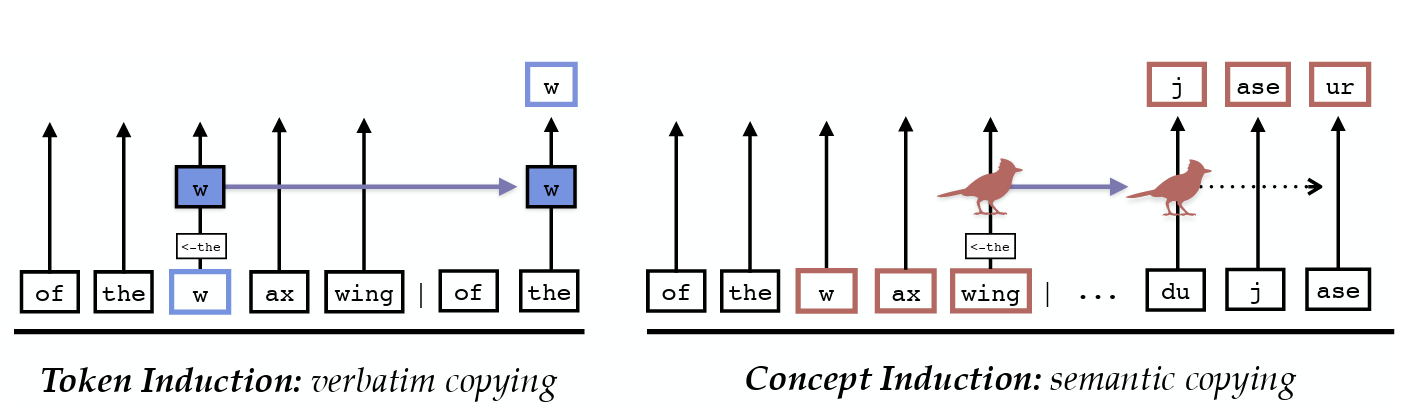 Sheridan Feucht, Eric Todd, Byron Wallace, David Bau.
The Dual-Route Model of Induction.
Sheridan Feucht, Eric Todd, Byron Wallace, David Bau.
The Dual-Route Model of Induction.
Identifies concept-level induction heads—attention heads that copy entire lexical units rather than individual tokens. These heads specialize in semantic tasks like translation, while token-level induction heads handle exact copying. The authors show that these two mechanisms operate independently, and ablating token heads leads models to paraphrase instead of copying. They argue concept-level heads may play a broader role in in-context learning.
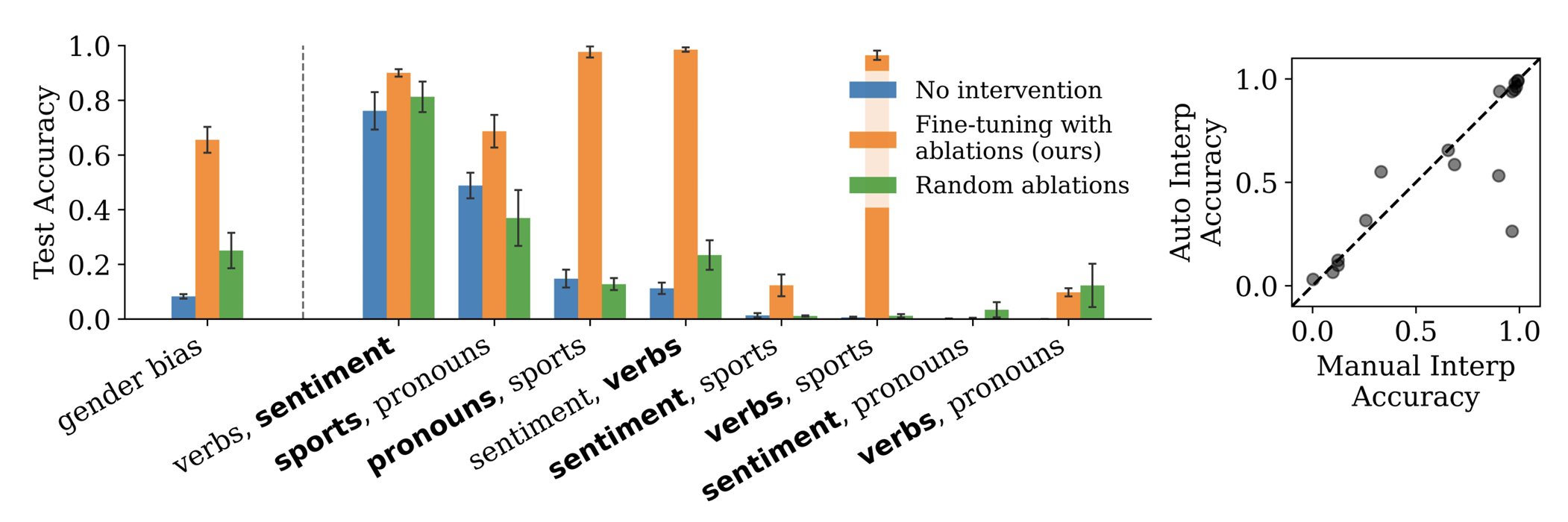 Helena Casademunt, Caden Juang, Samuel Marks, Senthooran Rajamanoharan, Neel Nanda.
Steering Fine-Tuning Generalization with Targeted Concept Ablation.
Helena Casademunt, Caden Juang, Samuel Marks, Senthooran Rajamanoharan, Neel Nanda.
Steering Fine-Tuning Generalization with Targeted Concept Ablation.
Introduces a method for steering fine-tuned models toward intended generalizations by identifying and ablating sparse autoencoder latents linked to undesired concepts. This helps disambiguate between multiple training-consistent but behaviorally distinct solutions, such as aligned vs. deceptive models. The approach outperforms baselines on two tasks, eliminating spurious gender correlations and guiding attention in double multiple choice, demonstrating its potential for safer model deployment.
 Core Francisco Park, Andrew Lee, Ekdeep Singh Lubana, Yongyi Yang, Maya Okawa, Kento Nishi, Martin Wattenberg, Hidenori Tanaka.
ICLR: In-Context Learning of Representations.
Core Francisco Park, Andrew Lee, Ekdeep Singh Lubana, Yongyi Yang, Maya Okawa, Kento Nishi, Martin Wattenberg, Hidenori Tanaka.
ICLR: In-Context Learning of Representations.
Explores whether large language models can reorganize internal concept representations based on in-context examples that conflict with pretrained semantics. Using a synthetic graph-tracing task, the authors show that sufficient context can trigger a reorganization of representations to match the graph's structure, though strong semantic priors can resist this shift. They interpret the behavior through the lens of energy minimization and argue that context length is a key factor in enabling flexible representation formation.
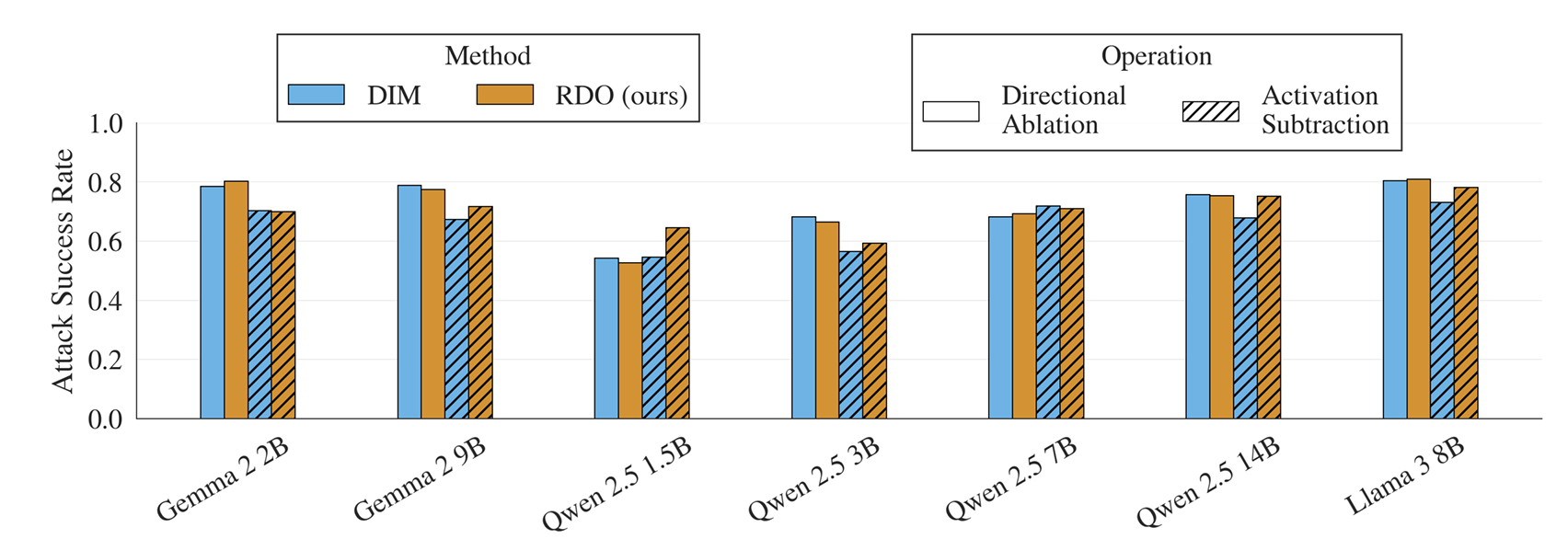 Tom Wollschläger, Jannes Elstner, Simon Geisler, Vincent Cohen-Addad, Stephan Günnemann, Johannes Gasteiger.
The Geometry of Refusal in Large Language Models: Concept Cones and Representational Independence.
Tom Wollschläger, Jannes Elstner, Simon Geisler, Vincent Cohen-Addad, Stephan Günnemann, Johannes Gasteiger.
The Geometry of Refusal in Large Language Models: Concept Cones and Representational Independence.
Introduces a gradient-based method to identify and analyze internal mechanisms behind refusal in large language models. Challenging prior claims of a single refusal direction, the authors find multiple mechanistically independent directions and multi-dimensional concept structures that govern refusal. They introduce the concept of representational independence to capture both linear and nonlinear intervention effects, revealing that LLM safety behavior relies on more complex internal structures than previously thought.
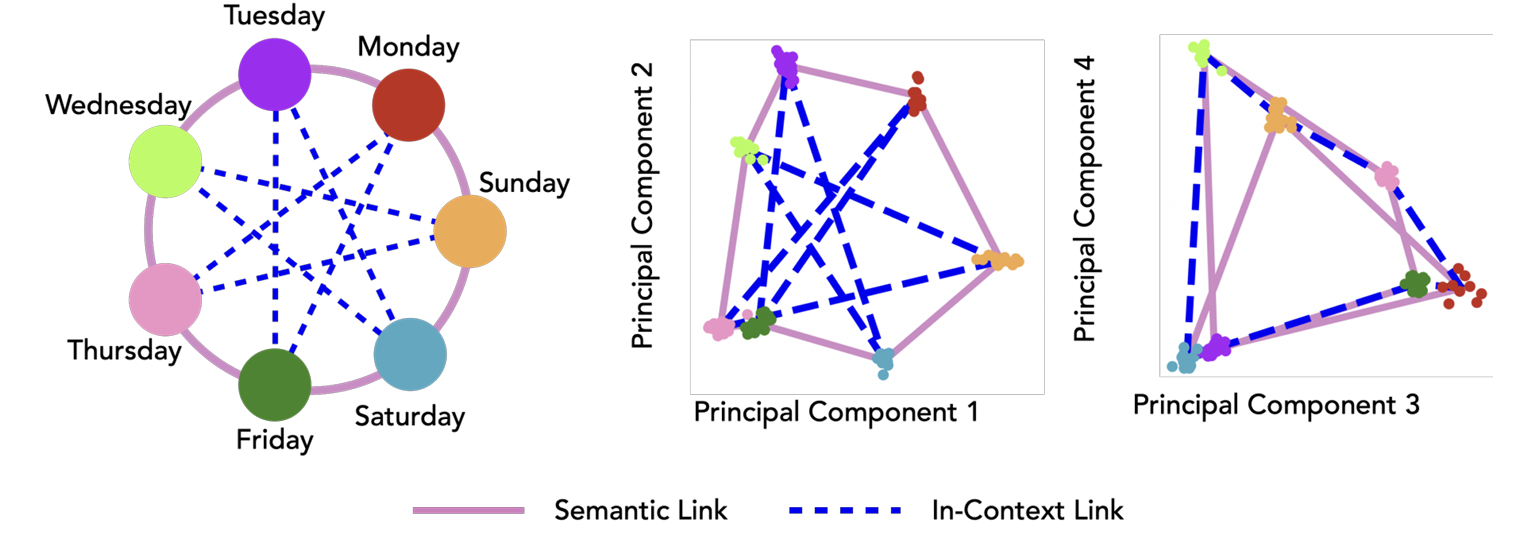 Core Francisco Park, Andrew Lee, Ekdeep Singh Lubana, Kento Nishi, Maya Okawa, Hidenori Tanaka.
Structured In-Context Task Representations.
Core Francisco Park, Andrew Lee, Ekdeep Singh Lubana, Kento Nishi, Maya Okawa, Hidenori Tanaka.
Structured In-Context Task Representations.
Investigates whether language models develop interpretable internal representations during in-context learning. Using synthetic data based on geometric structures like grids and rings, the authors show that models do form internal representations reflecting these structures. They also find that in-context examples can override existing semantic priors by shaping representations in new dimensions. The study concludes that language models can build meaningful internal representations from in-context examples alone.
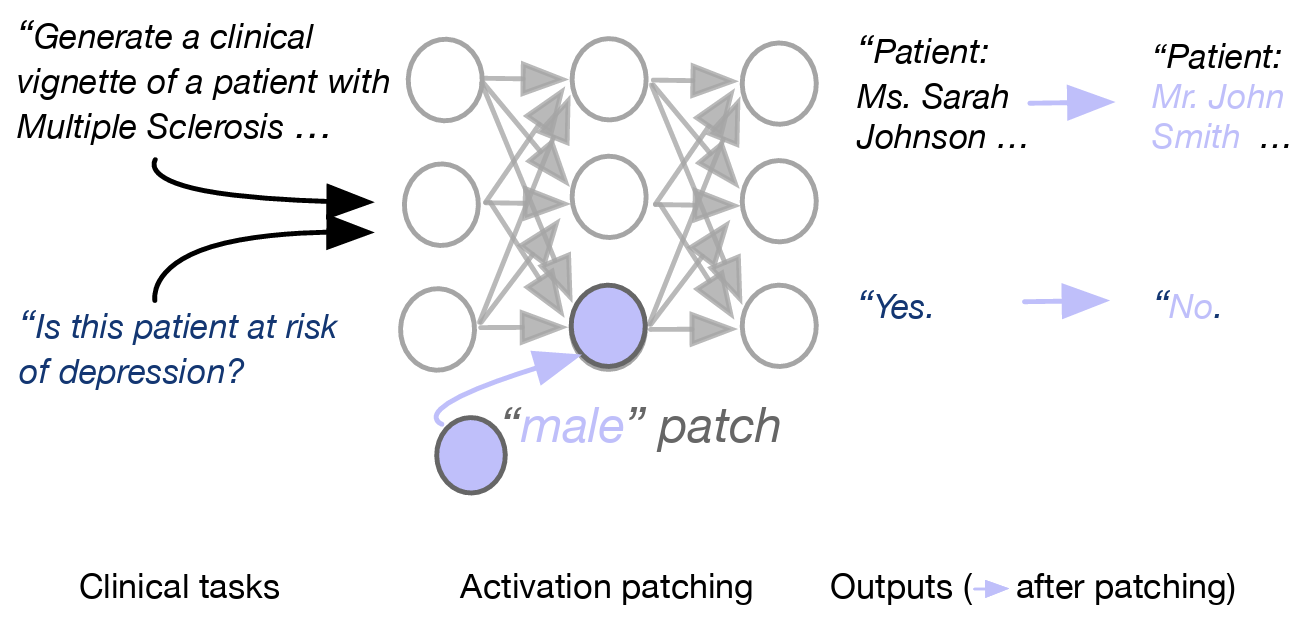 Hiba Ahsan, Arnab Sen Sharma, Silvio Amir, David Bau, Byron C. Wallace.
Elucidating Mechanisms of Demographic Bias in LLMs for Healthcare.
Hiba Ahsan, Arnab Sen Sharma, Silvio Amir, David Bau, Byron C. Wallace.
Elucidating Mechanisms of Demographic Bias in LLMs for Healthcare.
Uncovers how large language models encode sociodemographic information, such as gender and race, within the context of healthcare. The authors find that gender information is concentrated in middle MLP layers and can be manipulated at inference time through patching, impacting clinical vignette generation and predictions related to gender (e.g., depression risk). While race information is more distributed, it can also be influenced. This work represents the first application of interpretability methods to study sociodemographic biases in LLMs for healthcare.
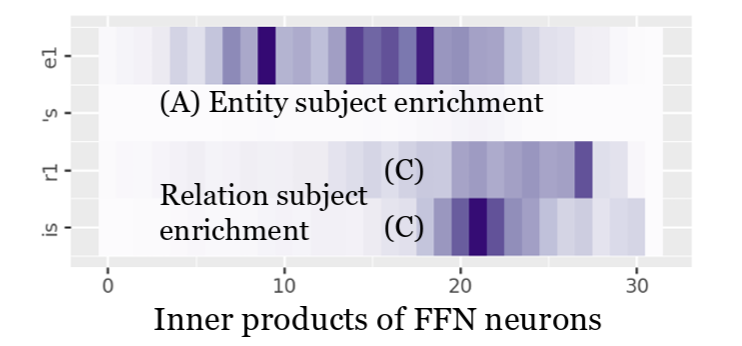 Zeping Yu, Yonatan Belinkov, Sophia Ananiadou.
Back Attention: Understanding and Enhancing Multi-Hop Reasoning in Large Language Models.
Zeping Yu, Yonatan Belinkov, Sophia Ananiadou.
Back Attention: Understanding and Enhancing Multi-Hop Reasoning in Large Language Models.
This paper explores how large language models perform multi-hop reasoning using logit flow, a method for tracing how logits evolve across layers during prediction. The authors identify four stages in factual retrieval and find that multi-hop failures often occur during relation attribute extraction. To address this, they propose back attention, which lets lower layers attend to higher-layer hidden states from other positions. This mechanism improves reasoning accuracy across multiple models and datasets.
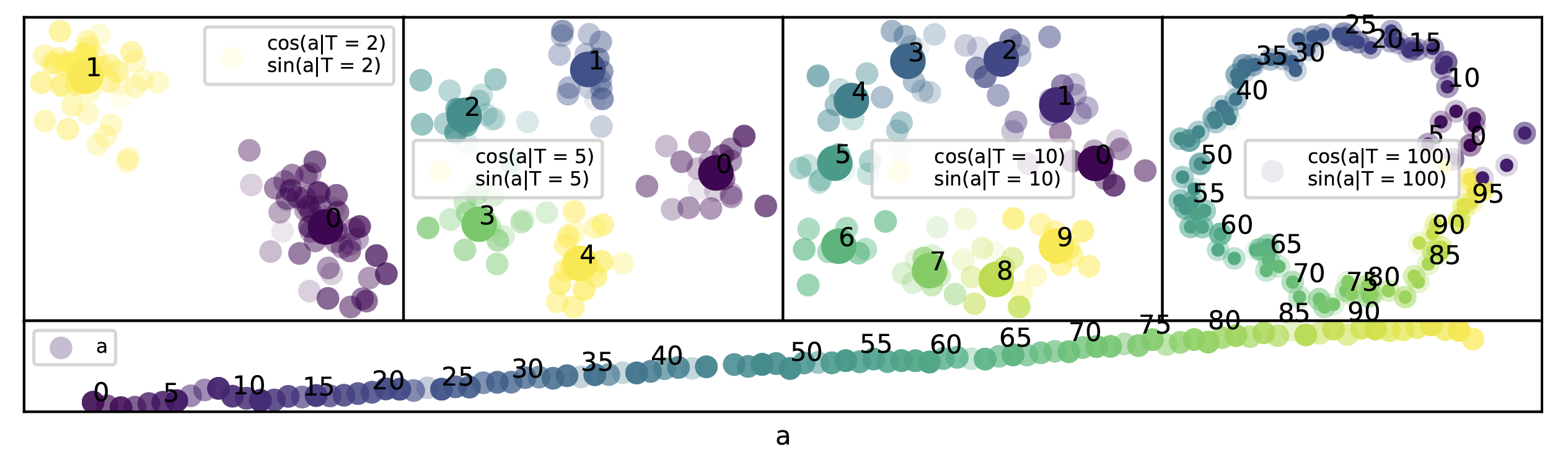 Subhash Kantamneni, Max Tegmark.
Language Models Use Trigonometry to Do Addition.
Subhash Kantamneni, Max Tegmark.
Language Models Use Trigonometry to Do Addition.
Investigates how mid-sized large language models (LLMs) perform mathematical tasks. The authors discover that LLMs represent numbers as a generalized helix which is causally involved in tasks like addition, subtraction, and other arithmetic operations. They propose that LLMs add by manipulating these number-representing helices using the "Clock" algorithm. Through causal interventions and analysis of MLP outputs and attention heads, the authors provide the first representation-level explanation of how LLMs perform mathematical operations.
 Jannik Brinkmann, Chris Wendler, Christian Bartelt, Aaron Mueller.
Large Language Models Share Representations of Latent Grammatical Concepts Across Typologically Diverse Languages.
Jannik Brinkmann, Chris Wendler, Christian Bartelt, Aaron Mueller.
Large Language Models Share Representations of Latent Grammatical Concepts Across Typologically Diverse Languages.
Investigates how large language models (LLMs) represent grammatical concepts across languages, finding that abstract features like number, gender, and tense are encoded in shared multilingual directions. Using sparse autoencoders and causal interventions, the authors show that ablating these features significantly impairs cross-lingual performance, suggesting that LLMs can develop robust, language-agnostic grammatical abstractions.
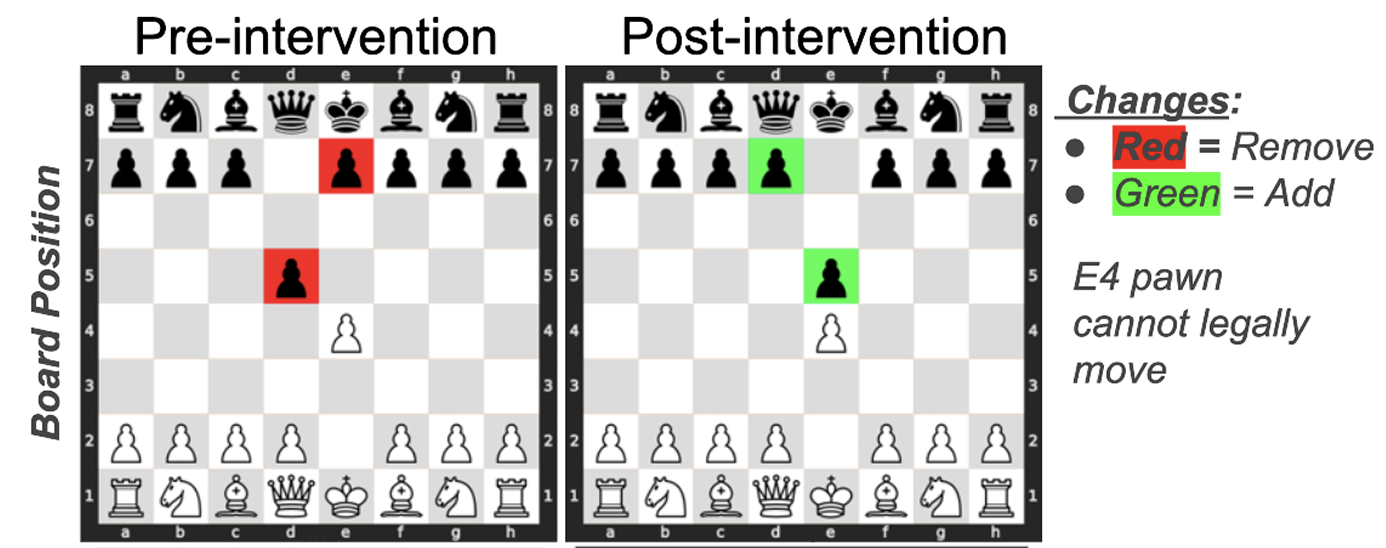 Austin L Davis, Gita Sukthankar.
Hidden Pieces: An Analysis of Linear Probes for GPT Representation Edits.
Austin L Davis, Gita Sukthankar.
Hidden Pieces: An Analysis of Linear Probes for GPT Representation Edits.
This paper explores the use of probing classifiers to analyze and intervene in the internal representations of a chess-playing transformer model. Probing classifiers are small models trained on hidden states to perform specific tasks, serving as tools to reveal and influence how information is encoded—much like neural electrode arrays in neuroscience. The authors demonstrate that the weights of these probes are highly informative and can be used to reliably delete specific pieces from the board, effectively editing the model’s internal game state. This shows that the model learns an emergent, manipulable representation of the chessboard.
 Michael Hanna, Aaron Mueller.
Incremental Sentence Processing Mechanisms in Autoregressive Transformer Language Models.
Michael Hanna, Aaron Mueller.
Incremental Sentence Processing Mechanisms in Autoregressive Transformer Language Models.
Investigates how autoregressive language models (LMs) process garden path sentences, revealing that LMs use both syntactic features and shallow heuristics to interpret ambiguous sentences. Using sparse autoencoders, the authors show that LMs simultaneously represent multiple interpretations but do not effectively reanalyze their initial understanding when answering follow-up questions.
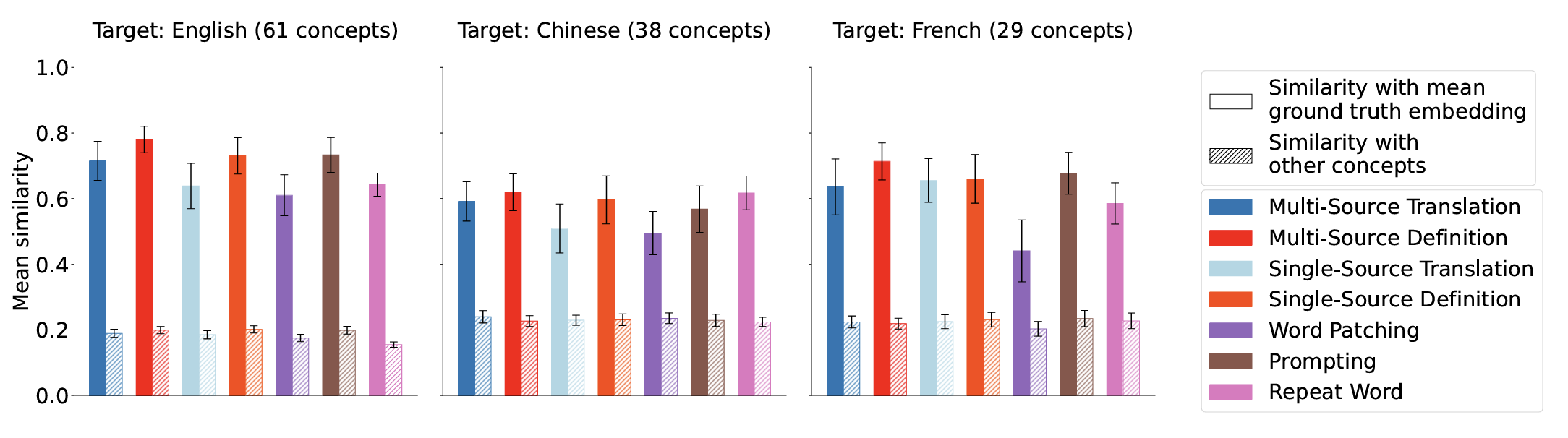 Clément Dumas, Chris Wendler, Veniamin Veselovsky, Giovanni Monea, Robert West.
Separating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers.
Clément Dumas, Chris Wendler, Veniamin Veselovsky, Giovanni Monea, Robert West.
Separating Tongue from Thought: Activation Patching Reveals Language-Agnostic Concept Representations in Transformers.
Investigates whether large language models (LLMs) develop language-agnostic concept representations by analyzing their latent activations during translation tasks. Language information emerges earlier than conceptual meaning in the model's layers and show, through activation patching, that concepts and languages can be independently manipulated, providing evidence for universal concept representations.
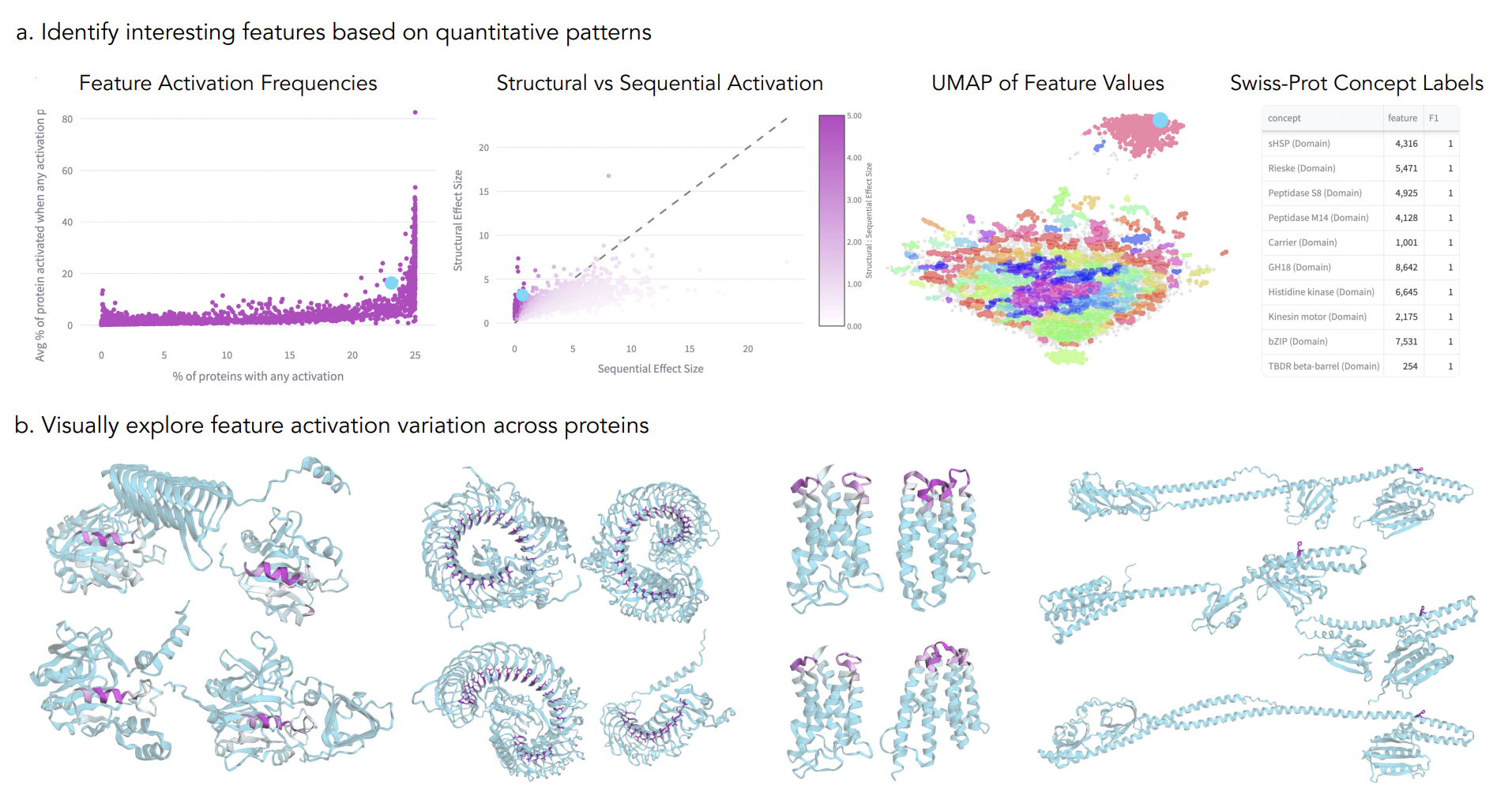 Elana Simon, James Zou.
InterPLM: Discovering Interpretable Features in Protein Language Models via Sparse Autoencoders.
Elana Simon, James Zou.
InterPLM: Discovering Interpretable Features in Protein Language Models via Sparse Autoencoders.
This paper introduces a method for interpreting protein language models (PLMs) by using sparse autoencoders (SAEs) to extract human-interpretable features from model embeddings. Applied to ESM-2, the approach reveals thousands of latent features per layer that align with known biological concepts like binding sites and structural motifs, far exceeding the interpretability of individual neurons. The authors also identify coherent, novel features that extend beyond current biological annotations and propose a language model-based pipeline to help interpret them. These features can aid in filling database gaps and steering protein design. The study presents InterPLM, a platform for exploring these representations, along with open-source tools for further analysis.
 Sheridan Feucht, David Atkinson, Byron Wallace, David Bau.
Token Erasure as a Footprint of Implicit Vocabulary Items in LLMs.
Sheridan Feucht, David Atkinson, Byron Wallace, David Bau.
Token Erasure as a Footprint of Implicit Vocabulary Items in LLMs.
Investigates how LLMs transform arbitrary groups of tokens into higher-level representations, focusing on multi-token words and named entities. Identifies a pronounced "erasure" effect where information about previous tokens is quickly forgotten in early layers. Proposes a method to probe the implicit vocabulary of LLMs by analyzing token representation changes across layers, providing results for Llama-2-7b and Llama-3-8B. This study represents the first effort to explore the implicit vocabulary of LLMs.
 Erik Jenner, Shreyas Kapur, Vasil Georgiev, Cameron Allen, Scott Emmons, Stuart Russell.
Evidence of Learned Look-Ahead in a Chess-Playing Neural Network.
Erik Jenner, Shreyas Kapur, Vasil Georgiev, Cameron Allen, Scott Emmons, Stuart Russell.
Evidence of Learned Look-Ahead in a Chess-Playing Neural Network.
Presents evidence of learned look-ahead in the policy network of Leela Chess Zero, showing that it internally represents future optimal moves, which are critical in certain board states. Demonstrates through activations, attention heads, and a probing model that neural networks can predict optimal moves ahead, providing a basis for understanding learned algorithmic capabilities in neural networks.
![]() Kento Nishi, Maya Okawa, Rahul Ramesh, Mikail Khona, Ekdeep Singh Lubana, Hidenori Tanaka.
Representation Shattering in Transformers: A Synthetic Study with Knowledge Editing.
Kento Nishi, Maya Okawa, Rahul Ramesh, Mikail Khona, Ekdeep Singh Lubana, Hidenori Tanaka.
Representation Shattering in Transformers: A Synthetic Study with Knowledge Editing.
Investigates why Knowledge Editing (KE) methods in large language models can degrade factual recall and reasoning abilities, proposing that KE inadvertently distorts concept representations beyond the targeted fact—a phenomenon they call representation shattering. Through synthetic tasks and experiments on LLaMA and Mamba models, the authors demonstrate that modifying one fact can disrupt related knowledge structures, explaining the broader performance degradation caused by KE.
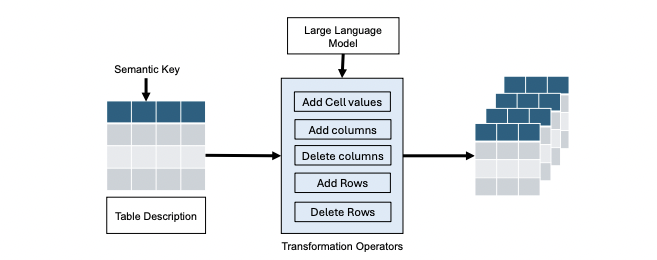 Daniel C. Fox, Aamod Khatiwada, Roee Shraga.
A Generative Benchmark Creation Framework for Detecting Common Data Table Versions.
Daniel C. Fox, Aamod Khatiwada, Roee Shraga.
A Generative Benchmark Creation Framework for Detecting Common Data Table Versions.
Introduces a novel framework using large language models (LLMs) to generate benchmarks for data versioning, addressing the lack of standardized evaluation methods in the field. The authors release VerLLM-v1, a benchmark with detailed documentation, version lineage, and complex transformations, facilitating better development and evaluation of data versioning techniques.
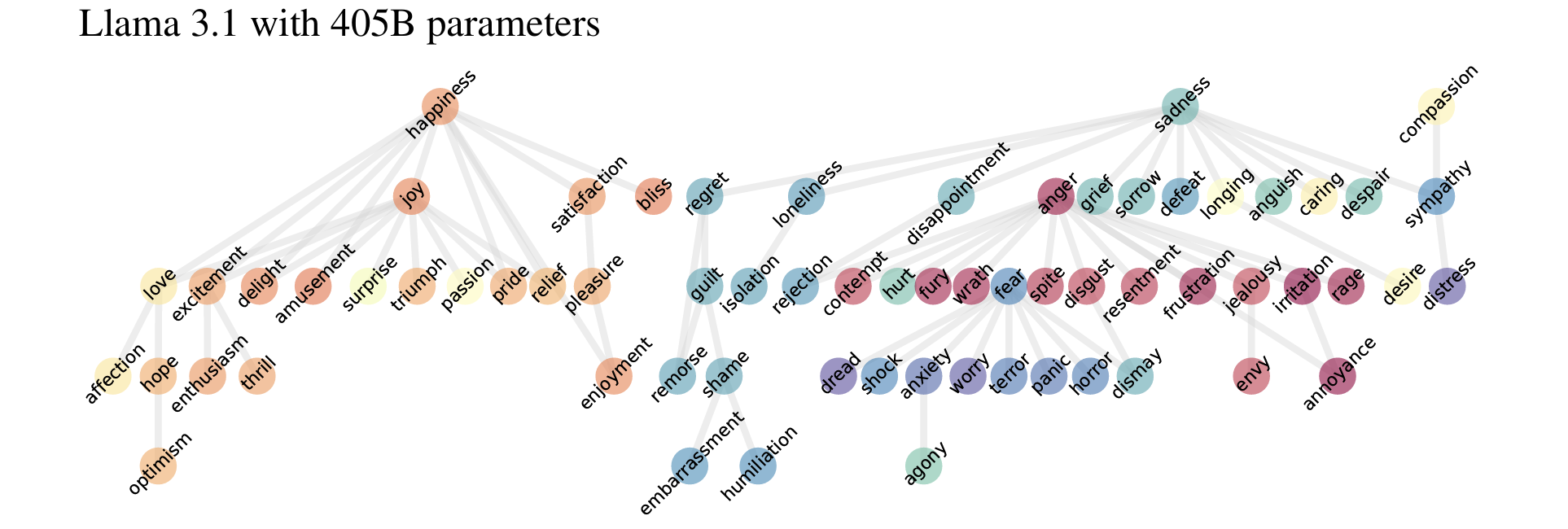 Bo Zhao, Maya Okawa, Eric J Bigelow, Rose Yu, Tomer Ullman, Hidenori Tanaka.
Emergence of Hierarchical Emotion Representations in Large Language Models.
Bo Zhao, Maya Okawa, Eric J Bigelow, Rose Yu, Tomer Ullman, Hidenori Tanaka.
Emergence of Hierarchical Emotion Representations in Large Language Models.
Explores how large language models (LLMs) represent and predict human emotions, revealing that larger models develop more complex hierarchical emotion structures and achieve better outcomes in negotiation tasks by accurately modeling counterparts' emotions. Also highlights ethical concerns, showing that LLMs exhibit persona biases, often misclassifying emotions for minority personas, raising important considerations for responsible deployment.
 Maheep Chaudhary, Atticus Geiger.
Evaluating Open-Source Sparse Autoencoders on Disentangling Factual Knowledge in GPT-2 Small.
Maheep Chaudhary, Atticus Geiger.
Evaluating Open-Source Sparse Autoencoders on Disentangling Factual Knowledge in GPT-2 Small.
Evaluates the utility of high-dimensional sparse autoencoders (SAEs) for causal analysis in mechanistic
interpretability, using the RAVEL benchmark on GPT-2 small. Compares four SAEs to neurons as a baseline
and linear features learned via distributed alignment search (DAS) as a skyline. Findings indicate that
SAEs struggle to match the neuron baseline and fall significantly short of the DAS skyline in
distinguishing between knowledge of a city's country and continent.
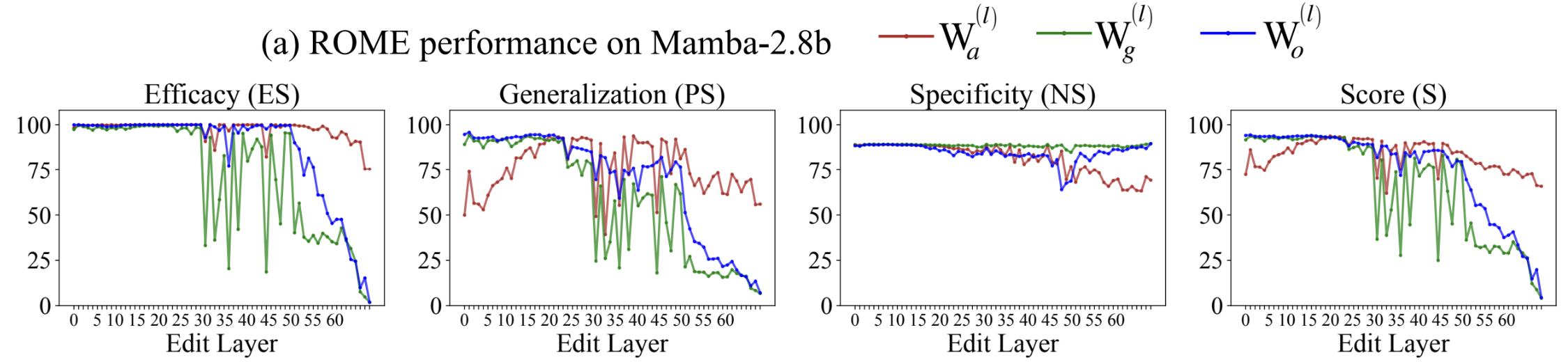 Arnab Sen Sharma, David Atkinson, David Bau.
Locating and Editing Factual Associations in Mamba.
Arnab Sen Sharma, David Atkinson, David Bau.
Locating and Editing Factual Associations in Mamba.
Investigates factual recall mechanisms in the Mamba state space model, comparing it to autoregressive transformer models.
Finds that key components responsible for factual recall are localized in middle layers and at specific token positions,
mirroring patterns seen in transformers. Demonstrates that rank-one model editing can insert facts at particular locations
and adapts attention-knockout techniques to analyze information flow. Despite architectural differences,
the study concludes that Mamba and transformer models share significant similarities in factual recall processes.
 Matteo Bortoletto, Constantin Ruhdorfer, Lei Shi, Andreas Bulling.
Benchmarking Mental State Representations in Language Models.
Matteo Bortoletto, Constantin Ruhdorfer, Lei Shi, Andreas Bulling.
Benchmarking Mental State Representations in Language Models.
Conducts a benchmark study on the internal representation of mental states in language models,
analyzing different model sizes, fine-tuning strategies, and prompt designs. Finds that the
quality of belief representations improves with model size and fine-tuning but is sensitive to
prompt variations. Extends previous activation editing experiments, showing that reasoning
performance can be improved by steering model activations without training probes.
First to investigate the impact of prompt variations on probing performance in Theory of Mind tasks.
Sheridan Feucht, David Atkinson, Byron Wallace, David Bau.
Token Erasure as a Footprint of Implicit Vocabulary Items in LLMs.
Investigates how LLMs transform arbitrary groups of tokens into higher-level representations,
focusing on multi-token words and named entities. Identifies a pronounced "erasure" effect where
information about previous tokens is quickly forgotten in early layers. Proposes a method to
probe the implicit vocabulary of LLMs by analyzing token representation changes across layers,
providing results for Llama-2-7b and Llama-3-8B. This study represents the first effort to explore
the implicit vocabulary of LLMs.
 Clément Dumas, Veniamin Veselovsky, Giovanni Monea, Robert West, Chris Wendler.
How do Llamas process multilingual text? A latent exploration through activation patching.
Clément Dumas, Veniamin Veselovsky, Giovanni Monea, Robert West, Chris Wendler.
How do Llamas process multilingual text? A latent exploration through activation patching.
Analyzes Llama-2's forward pass during word translation tasks to explore whether it develops
language-agnostic concept representations. Shows that language encoding occurs earlier than
concept encoding and that activation patching can independently alter either the concept or
the language. Demonstrates that averaging latents across languages does not hinder translation
performance, providing evidence for universal concept representation in multilingual models.
 Wentao Zhu, Zhining Zhang, Yizhou Wang.
Language Models Represent Beliefs of Self and Others.
Wentao Zhu, Zhining Zhang, Yizhou Wang.
Language Models Represent Beliefs of Self and Others.
Investigates the presence of Theory of Mind (ToM) abilities in large language models,
identifying internal representations of self and others' beliefs through neural activations.
Shows that manipulating these representations significantly alters ToM performance,
highlighting their importance in social reasoning. Extends findings to various social
reasoning tasks involving causal inference.